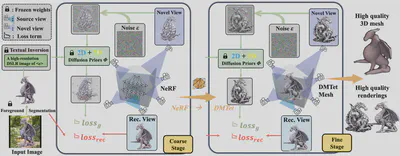
We present Magic123, a two-stage coarse-to-fine approach for high-quality, textured 3D mesh generation from a single image in the wild using both 2D and 3D priors. In the first stage, we optimize a neural radiance field to produce a coarse geometry. In the second stage, we adopt a memory-efficient differentiable mesh representation to yield a high-resolution mesh with a visually appealing texture. In both stages, the 3D content is learned through reference-view supervision and novel-view guidance by a joint 2D and 3D diffusion prior. We introduce a trade-off parameter between the 2D and 3D priors to control the details and 3D consistencies of the generation. Magic123 demonstrates a significant improvement over previous image-to-3D techniques, as validated through extensive experiments on diverse synthetic and real-world images.
International Conference on Learning Representations
Magic123: One Image to High-Quality 3D Object Generation Using Both 2D and 3D Diffusion Priors
Method
We introduce Magic123, a coarse-to-fine pipeline for single-image 3D object generation. The pipeline leverages:
A coarse stage using a neural radiance field for smooth geometry approximation.
A fine stage using a memory-efficient differentiable mesh for high-resolution geometry and texture.
Figure: Our two-stage pipeline. In the coarse stage, we optimize a NeRF for initial geometry; in the fine stage, we refine geometry and texture using a differentiable mesh representation.
Overall Objective
We optimize both stages with a combination of novel view guidance, reference-view reconstruction, and regularization losses:
\(\mathcal{L}_g\): Novel view guidance driven by diffusion priors.
\(\mathcal{L}_{rec}\): Reference-view reconstruction aligning the rendered object to the single reference image.
\(\mathcal{L}_d\): Depth regularization preventing overly flat or caved-in geometries.
\(\mathcal{L}_n\): Normal smoothness reducing high-frequency artifacts.
Joint 2D and 3D Prior
To recover plausible geometry from a single view, we employ both a 2D image prior (e.g., Stable Diffusion) and a 3D-aware prior (e.g., Zero-1-to-3). The corresponding gradient can be summarized as:
By tuning \(\lambda_{2D}\) and \(\lambda_{3D}\), we can balance high detail (from the 2D prior) and consistent geometry (from the 3D prior).
In practice, we fix \(\lambda_{3D}\) and adjust \(\lambda_{2D}\) to trade off between detail and geometric consistency. This joint prior ensures more robust 3D structures while preserving fine details from the reference image.